wfuzz安装
wfuzz是在python2上运行
对于使用Python 3的开发人员来说,您需要
1 | sudo apt-get install python3 python-dev python3-dev \ |
使用Python 2,您需要
1 | sudo apt-get install python-dev \ |
安装pycurl
Windows
① pip install wheel
② http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载对应的包
③ pip install pycurl-7.43.1-cp37-cp37m-win_amd64.whl
④ pip install wfuzz
Linux
1 | wget https://curl.haxx.se/download/curl-7.61.0.tar.gz |
在刷src时候我们经常会对一些的参数进行fuzz,古话说得好万物皆可fuzzing。我在测试的时候遇到不少案例,还有乌云上表哥们发的文章经常会用到fuzz,下面介绍的就是很早之前就听说的一款工具,但一直没去使用的wfuzz。
说说fuzz的案例都会有哪些呢?
① callback参数有时不显示,需要fuzz进行测试,我们通常加参数去爆破有可能就能挖到jsonp还有xss
② 上传漏洞,通过替换后缀查看什么文件可以成功的上传
③ 备份文件的爆破,查看有无越权漏洞,越权下载配置不当放在/var/www/r.rar文件
④ 类似payload 的bypass,例如ssrf的十六进制和ipv6的payload,这些bypass以后找到案例再写文章分享出来
⑤ key师傅分享的一个案例,把post请求改为get

简单介绍
开始进入正题,介绍wfuzz的使用方法
1 | pip install wfuzz #安装wfuzz |
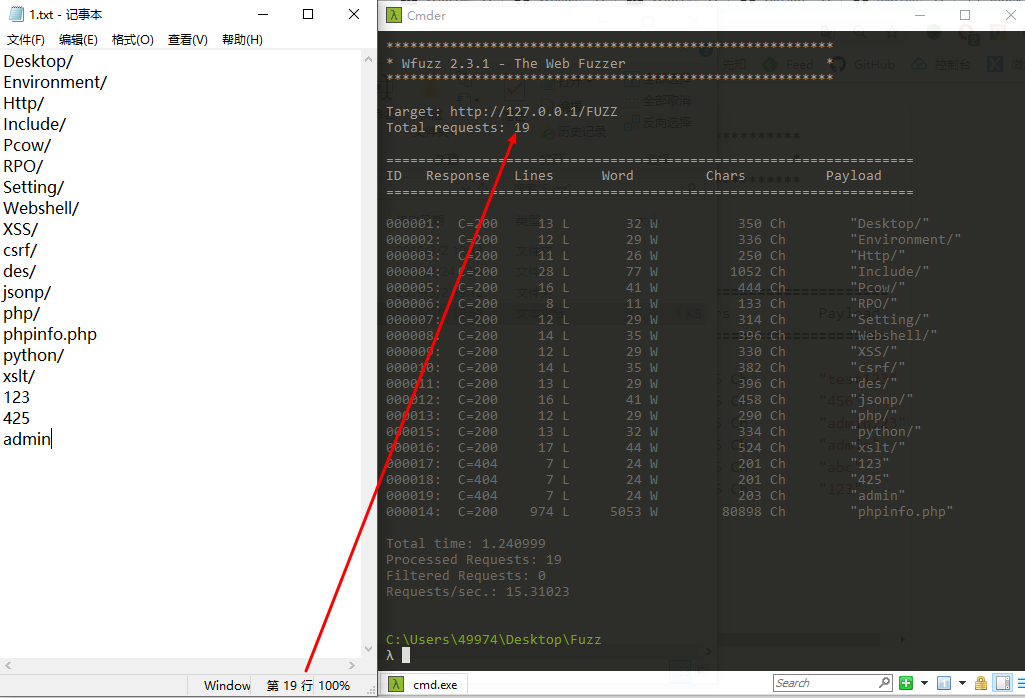
ID、Response、 Lines、Word、Chars、Payload这一行,从左往右看,依次是编号、响应状态码、响应报文行数、响应报文字数、响应报文正字符数、测试使用的Payload。
1.1 模块
1 | wfuzz -e payloads #wfuzz所拥有的模块 |
1 | burpstate |返回Burp状态的模糊结果。 |
我们可以使用下面命令查看每个模块的详情
1 | wfuzz -z help --slice "names" |
1.1.1 encoder
encoder的作用是将payload进行编码或加密。 wfuzz的encoder列表如下:
1 | Available encoders: |
1.1.2 iterator
wfuzz的iterator提供了针对多个payload的处理方式。 itorators的列表如下:
1 | Available iterators: |
1.1.3 printer
wfuzz的printers用于控制输出打印。 printers列表如下:
1 | Available printers: |
1.1.4. scripts
scripts列表如下:
1 | Available scripts: |
1.2 内置工具
1.2.1 wfencode 工具
这是wfuzz自带的一个加密/解密(编码/反编码)工具,目前支持内建的encoders的加/解密。
1 | wfencode -e base64 123456 |
1.2.2 wfpayloa3d工具
wfpayload是payload生成工具
1 | wfpayload -z range,0-10 |
1.2.3 wxfuzz 工具
这个看源码是一个wxPython化的wfuzz,也就是GUI图形界面的wfuzz。目前需要wxPython最新版本才能使用,但是在ParrotOS和Kali上都无法正常安装成功,问题已在GitHub提交Issue,期待开发者的回复中…
1.2.4 wfuzz命令中文帮助
1 | Usage: wfuzz [options] -z payload,params <url> |
使用方法
2.1 简单使用
2.1.1 多个参数FUZZ
使用-z 或-w 参数可以同时指定多个字典,这时相应的占位符应设置为 FUZZ,FUZ2Z,FUZ3Z,….,FUZnZ, 其中n代表了占位序号。
例如想要同时爆破目录、文件名、后缀,可以这样来玩:
1 | wfuzz -w 目录字典路径 -w 文件名字典路径 -w 后缀名字典路径 URL/FUZZ/FUZ2Z.FUZ3Z |
2.1.2 过滤器
通过--hc,--hl,--hw,--hh参数可以隐藏某些HTTP响应。
--hc根据响应报文状态码进行隐藏(hide code)--hl根据响应报文行数进行隐藏(hide lines)--hw根据响应报文字数进行隐藏(hide word)--hh根据响应报文字符进行隐藏(hide chars 这里因为code和chars首字母都是c,–hc参数已经有了,所以hide chars的参数就变成了–hh)
结合使用:
1 | wfuzz -w wordlist --hc 302 --hl 7 --hw 18 --hh 222 https://www.baidu.com/FUZZ |
2.1.3 显示响应结果
显示响应结果的使用方法跟隐藏时的原理一样,只不过参数变为了:--sc(show code),--sl(show lines),--sw(show word),--sh(show chars)。
2.1.4 使用Baseline(基准线)
过滤器可以是某个HTTP响应的引用,这样的引用我们称为Baseline。之前的使用--hh进行过滤的例子中,还可以使用下面的命令代替:
1 | wfuzz -w wordlist --hh BBB https://www.baidu.com/FUZZ{404there} |
首先解释下https://www.baidu.com/FUZZ{404there}的意思,这里代表wfuzz第一个请求是请求https://www.baidu.com/404there这个网址,在{ }内的值用来指定wfuzz第一个请求中的FUZZ占位符,而这第一个请求被标记为BBB(BBB不能换成别的)基准线;其次这里使用的参数是--hh,也就是以BBB这条请求中的Chars为基准,其他请求的Chars值与BBB相同则隐藏。
2.1.5 使用正则表达式过滤
wfuzz参数--ss和--hs可以使用正则表达式来对返回的结果过滤。
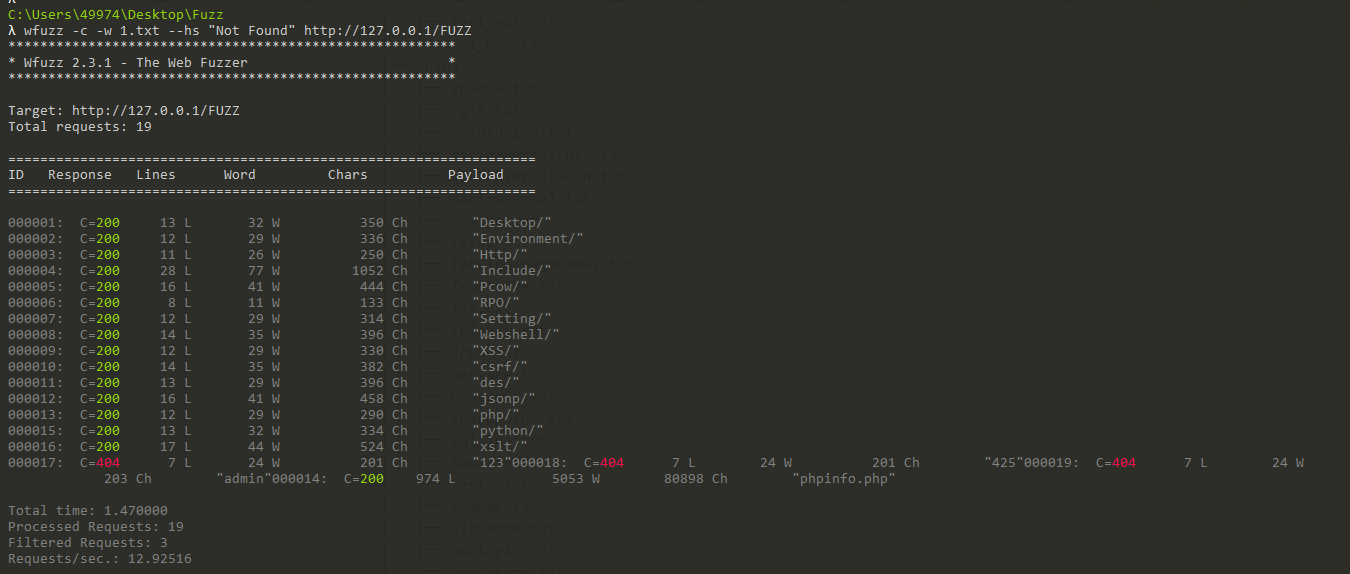
e.g. 在这里一个网站自定义返回页面的内容中包含Not Found,想根据这个内容进行过滤可以使用如下的命令:
1 | wfuzz -c -w wordlist --hs "Not Found" http://127.0.0.1/FUZZ |
2.2 进阶使用
2.2.1 遍历枚举参数值
假如你发现了一个未授权漏洞,地址为:http://127.0.0.1/getuser.php?uid=123 可获取uid为123的个人信息
uid参数可以遍历,已知123为三位数纯数字,需要从000-999进行遍历,也可以使用wfuzz来完成:
1 | wfuzz -z range,000-999 http://127.0.0.1/getuser.php?uid=FUZZ |
使用payloads模块类中的range模块进行生成。
2.2.2 POST请求测试
发现一个登录框,没有验证码,想爆破弱口令账户。
请求地址为:http://127.0.0.1/login.php
POST请求正文为:username=&password=
使用wfuzz测试:
1 | wfuzz -w userList -w pwdList -d "username=FUZZ&password=FUZ2Z" http://127.0.0.1/login.php |
-d参数传输POST请求正文。
2.2.3 Cookie测试
上文 遍历枚举参数值 中说到有未授权漏洞,假设这个漏洞是越权漏洞,要做测试的肯定需要让wfuzz知道你的Cookie才能做测试。
如下命令即可携带上Cookie:
1 | wfuzz -z range,000-999 -b session=session -b cookie=cookie http://127.0.0.1/getuser.php?uid=FUZZ |
-b参数指定Cookie,多个Cookie需要指定多次,也可以对Cookie进行测试,仍然使用FUZZ占位符即可。
2.2.4 HTTP Headers测试
e.g. 发现一个刷票的漏洞,这个漏洞需要伪造XFF头(IP)可达到刷票的效果,投票的请求为GET类型,地址为:http://127.0.0.1/get.php?userid=666。
那么现在我想给userid为666的朋友刷票,可以使用wfuzz完成这类操作:
1 | wfuzz -z range,0000-9999 -H "X-Forwarded-For: FUZZ" http://127.0.0.1/get.php?userid=666 |
-H指定HTTP头,多个需要指定多次(同Cookie的-b参数)。
2.2.5 测试HTTP请求方法(Method)
e.g. 想测试一个网站(http://127.0.0.1/)支持哪些HTTP请求方法
使用wfuzz:
1 | wfuzz -z list,"GET-POST-HEAD-PUT" -X FUZZ http://127.0.0.1/ |
这条命了中多了 -z list 和 -X 参数,-z list可以自定义一个字典列表(在命令中体现),以-分割;-X参数是指定HTTP请求方法类型,因为这里要测试HTTP请求方法,后面的值为FUZZ占位符。
2.2.6 使用代理
做测试的时候想使用代理可以使用如下命令:
1 | wfuzz -w wordlist -p proxtHost:proxyPort:TYPE URL/FUZZ |
-p参数指定主机:端口:代理类型,例如我想使用ssr的,可以使用如下命令:
1 | wfuzz -w wordlist -p 127.0.0.1:1087:SOCKS5 URL/FUZZ |
多个代理可使用多个-p参数同时指定,wfuzz每次请求都会选取不同的代理进行。
2.2.7 认证
想要测试一个需要HTTP Basic Auth保护的内容可使用如下命令:
1 | wfuzz -z list,"username-password" --basic FUZZ:FUZZ URL |
wfuzz可以通过--basec --ntml --digest来设置认证头,使用方法都一样:
1 | --basec/ntml/digest username:password |
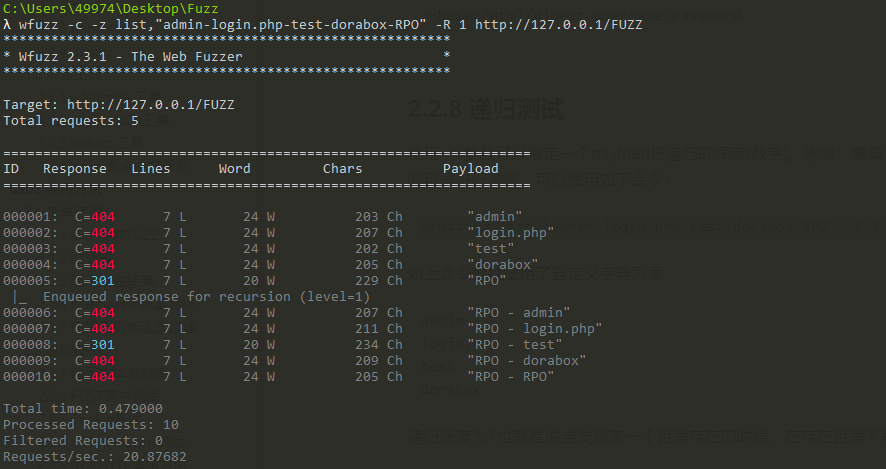
2.2.8 递归测试
使用-R参数可以指定一个payload被递归的深度(数字)。例如:爆破目录时,我们想使用相同的payload对已发现的目录进行测试,可以使用如下命令:
1 | wfuzz -z list,"admin-login.php-test-dorabox-RPO" -R 1 http://127.0.0.1/FUZZ |
如上命令就是使用了自定义字典列表:
1 | admin |
递归深度为1也就是说当发现某一个目录存在的时候,在存在目录下再递归一次字典。
2.2.9 并发和间隔
wfuzz提供了一些参数可以用来调节HTTP请求的线程
e.g. 你想测试一个网站的转账请求是否存在HTTP并发漏洞(条件竞争)
请求地址:http://127.0.0.1/dorabox/race_condition/pay.php
POST请求正文:money=1
使用如下命令:
1 | wfuzz -z range,0-20 -t 20 -d "money=1" http://127.0.0.1/dorabox/race_condition/pay.php?FUZZ |
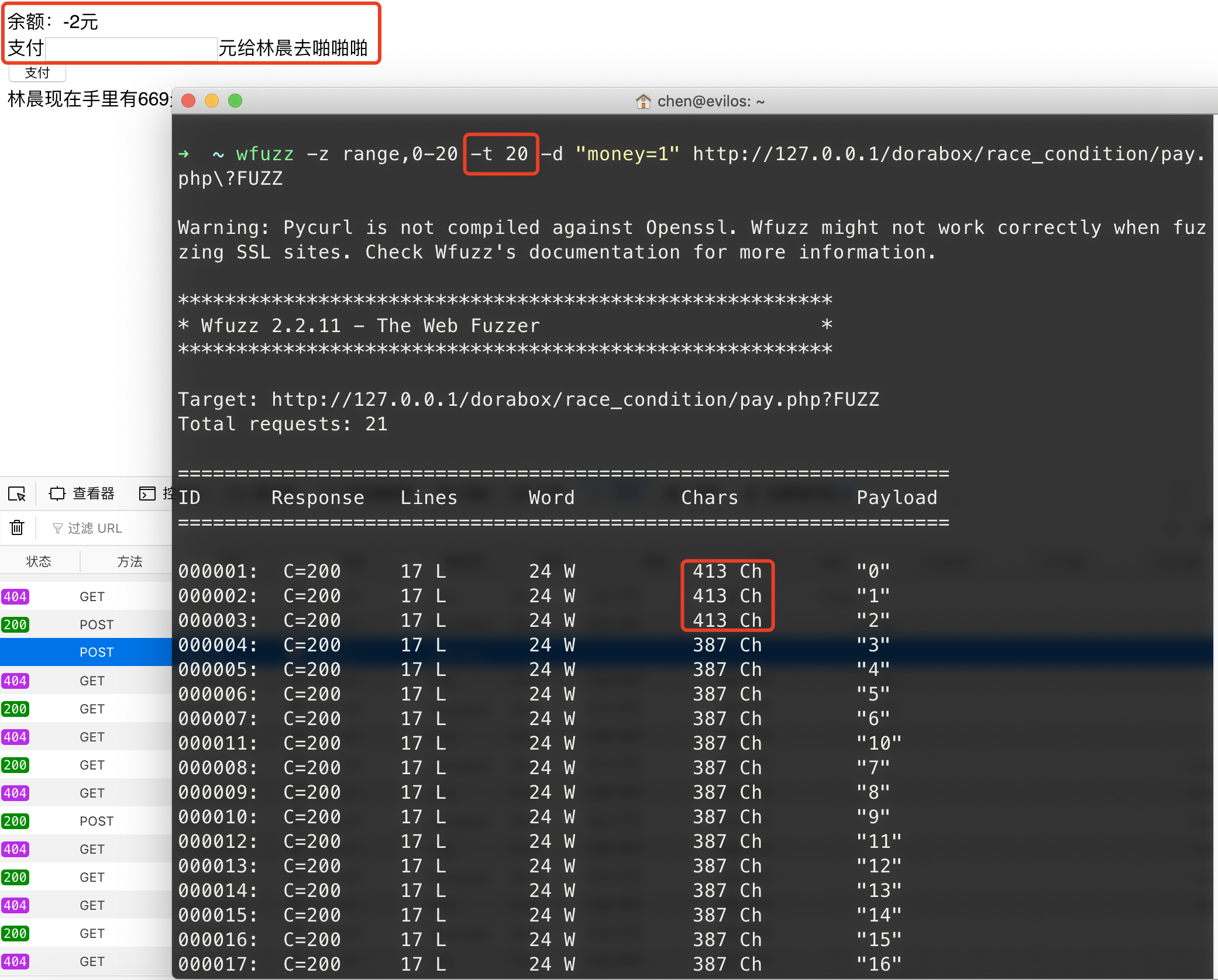
测试并发要控制请求次数,在这里为使用range模块生成0-20,然后将FUZZ占位符放在URL的参数后不影响测试即可,主要是用-t参数设置并发请求,该参数默认设置都是10。
另外使用-s参数可以调节每次发送HTTP的时间间隔。
2.2.10 保存测试结果
wfuzz通过printers模块来将结果以不同格式保存到文档中,一共有如下几种格式:
1 | raw | `Raw` output format |
将结果以json格式输出到文件的命令如下:
1 | $ wfuzz -f outfile,json -w wordlist URL/FUZZ |
使用-f参数,指定值的格式为输出文件位置,输出格式。
2.3 高阶功法
2.3.1 Iterators
BurpSuite的Intruder模块中Attack Type有Sniper(狙击手)、Battering ram(撞击物)、Pitchfork(相交叉)、Cluster bomb(集束炸弹)~
wfuzz也可以完成这样的功能,将不同的字典的组合起来,那就是Iterators模块。
使用参数-m 迭代器,wfuzz自带的迭代器有三个:zip、chain、product,如果不指定迭代器,默认为product迭代器。
zip
命令:
1 | wfuzz -z range,0-9 -w dict.txt -m zip http://127.0.0.1/ip.php?FUZZ=FUZ2Z |
结果如下:
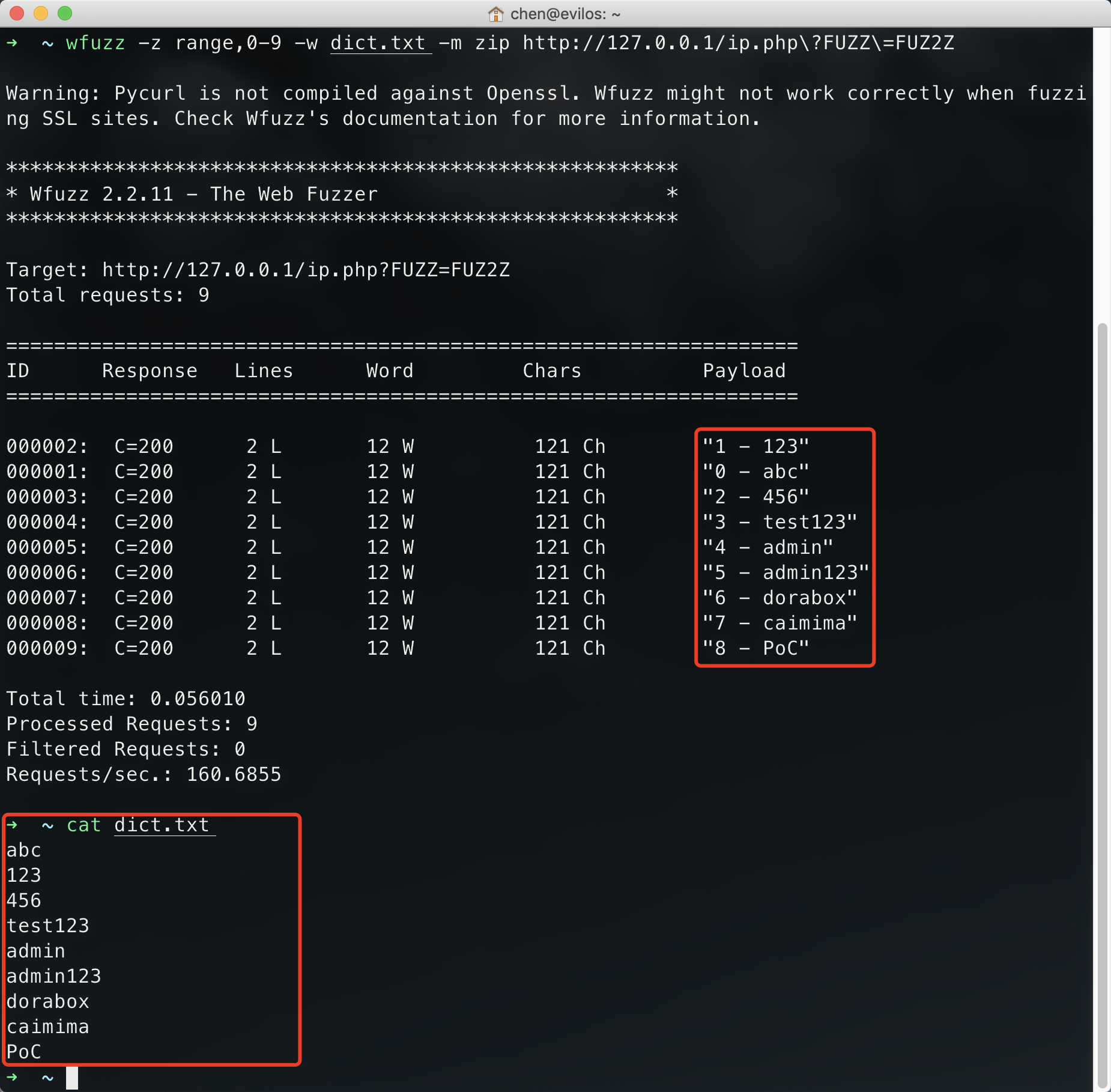
该命令的意思:设置了两个字典。两个占位符,一个是range模块生成的0、1、2、3、4、5、6、7、8、910个数字,一个是外部字典dict.txt的9行字典,使用zip迭代器组合这两个字典发送。
zip迭代器的功能:字典数相同、一一对应进行组合,如果字典数不一致则多余的抛弃掉不请求,如上命令结果就是数字9被抛弃了因为没有字典和它组合。
chain
命令:
1 | wfuzz -z range,0-9 -w dict.txt -m chain http://127.0.0.1/ip.php?FUZZ |
结果如下:
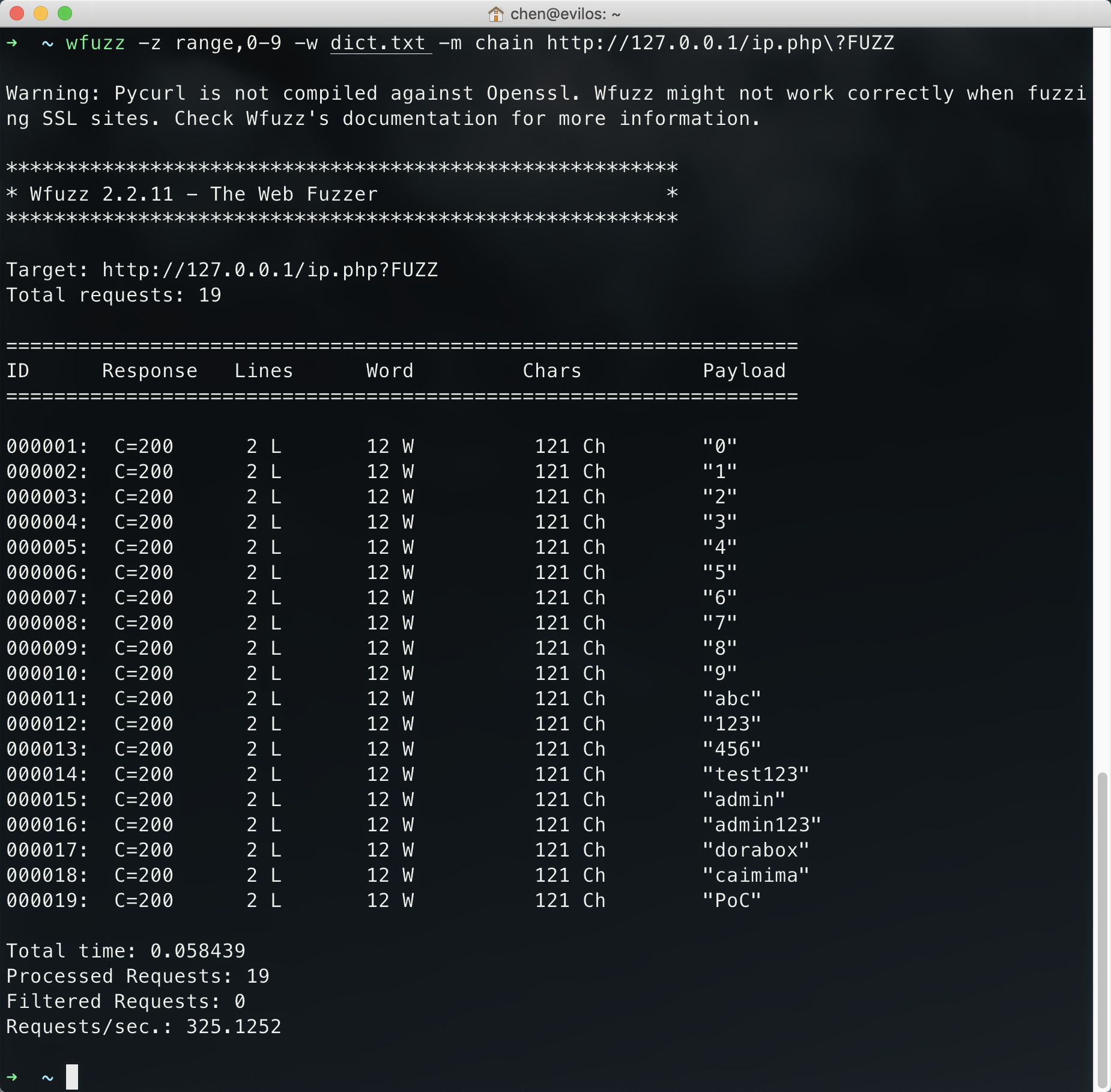
该命令设置了两个字典,一个占位符FUZZ,使用chain迭代器组合这两个字典发送。
chain迭代器的功能:通过返回结果就能看出来chain迭代器的功能了,这个迭代器是将所有字典全部整合(不做组合)放在一起然后传入占位符FUZZ中。
product
命令:
1 | wfuzz -z range,0-2 -w dict.txt -m product http://127.0.0.1/ip.php?FUZZ=FUZ2Z |
结果如下:
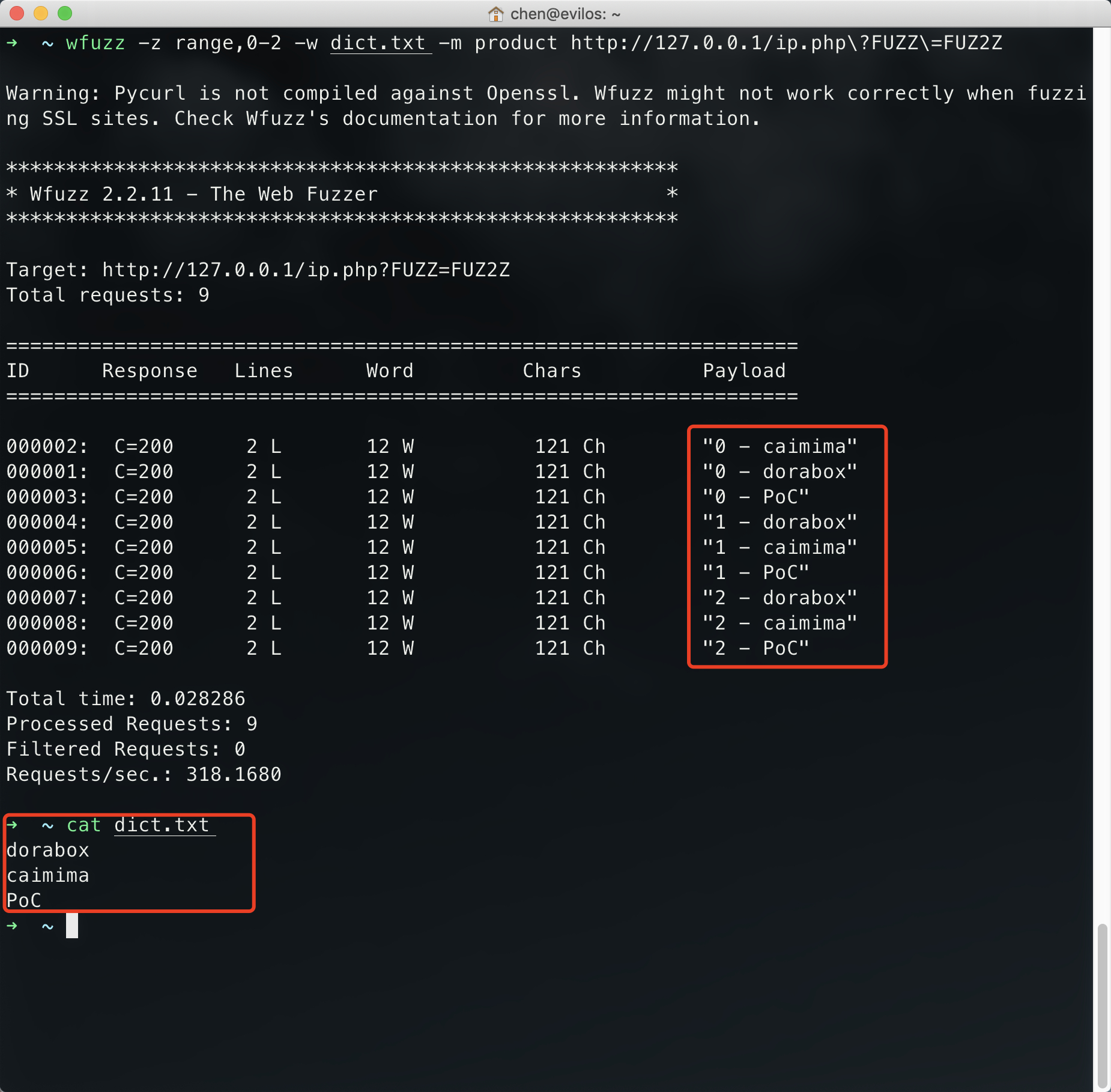
该命令的意思:设置了两个字典,两个占位符,一个是range模块生成的0、1、2 3个数字,一个是外部字典dict.txt的3行字典,使用product迭代器组合这两个字典发送。
product迭代器的功能:通过返回结果,知道了请求总数为9,请求的payload交叉组合:
2.3.2 Encoders
wfuzz中encoders模块可以实现编码解码、加密,它支持如下图中所列转换功能:
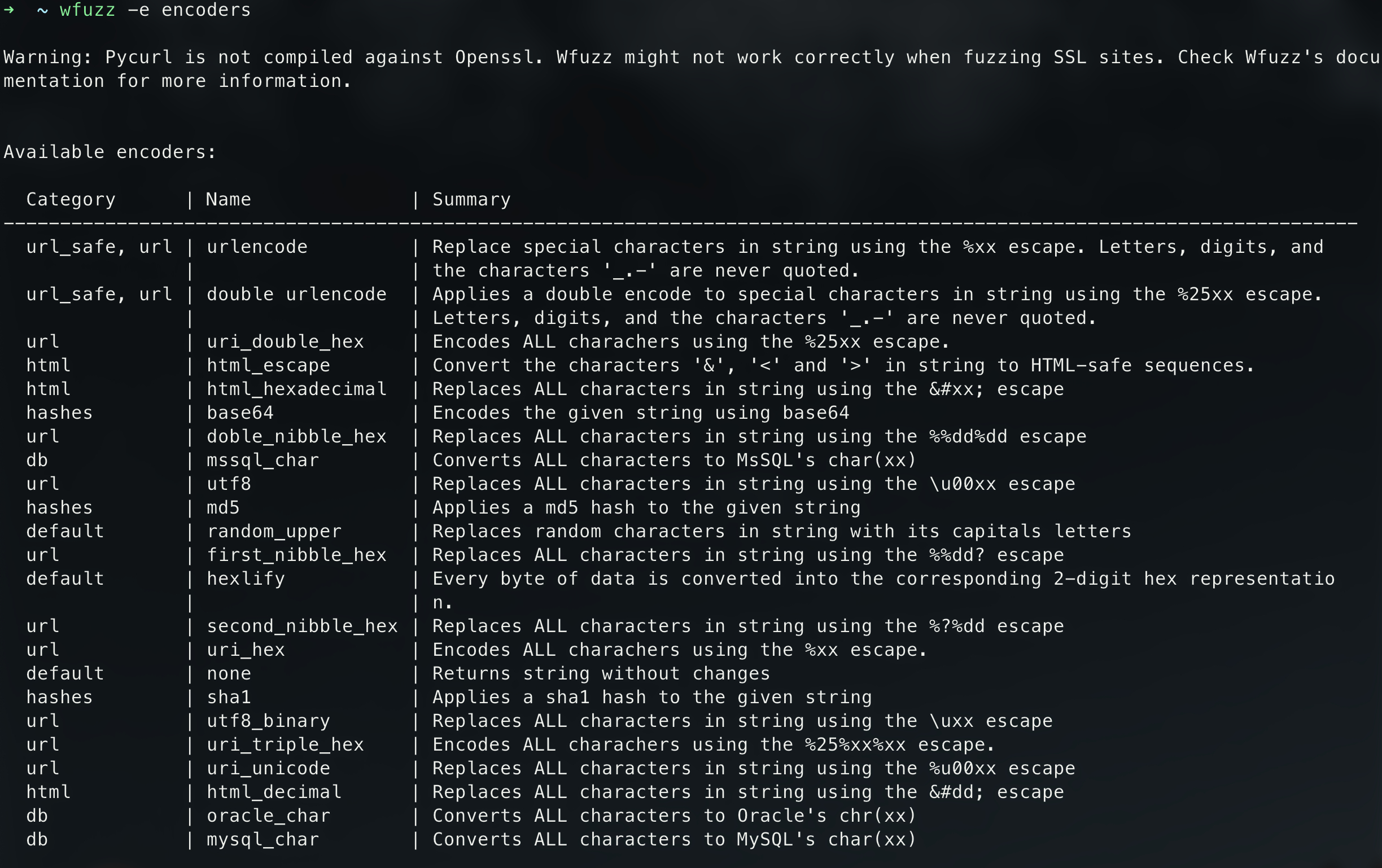
使用Encoders
正常使用:
wfuzz -z file --zP fn=wordlist,encoder=md5 URL/FUZZ看过第一章的应该都能理解意思了,这里新增的就是
encoder=md5,也就是使用Encoders的md5加密。wfuzz -z file,wordlist,md5 URL/FUZZ这里简写了第一条命令,一般都使用这条命令来调用Encoders
使用多个Encoder:
多个转换,使用一个
-号分隔的列表来指定wfuzz -z file,dict.txt,md5-base64 http://127.0.0.1/ip.php\?FUZZ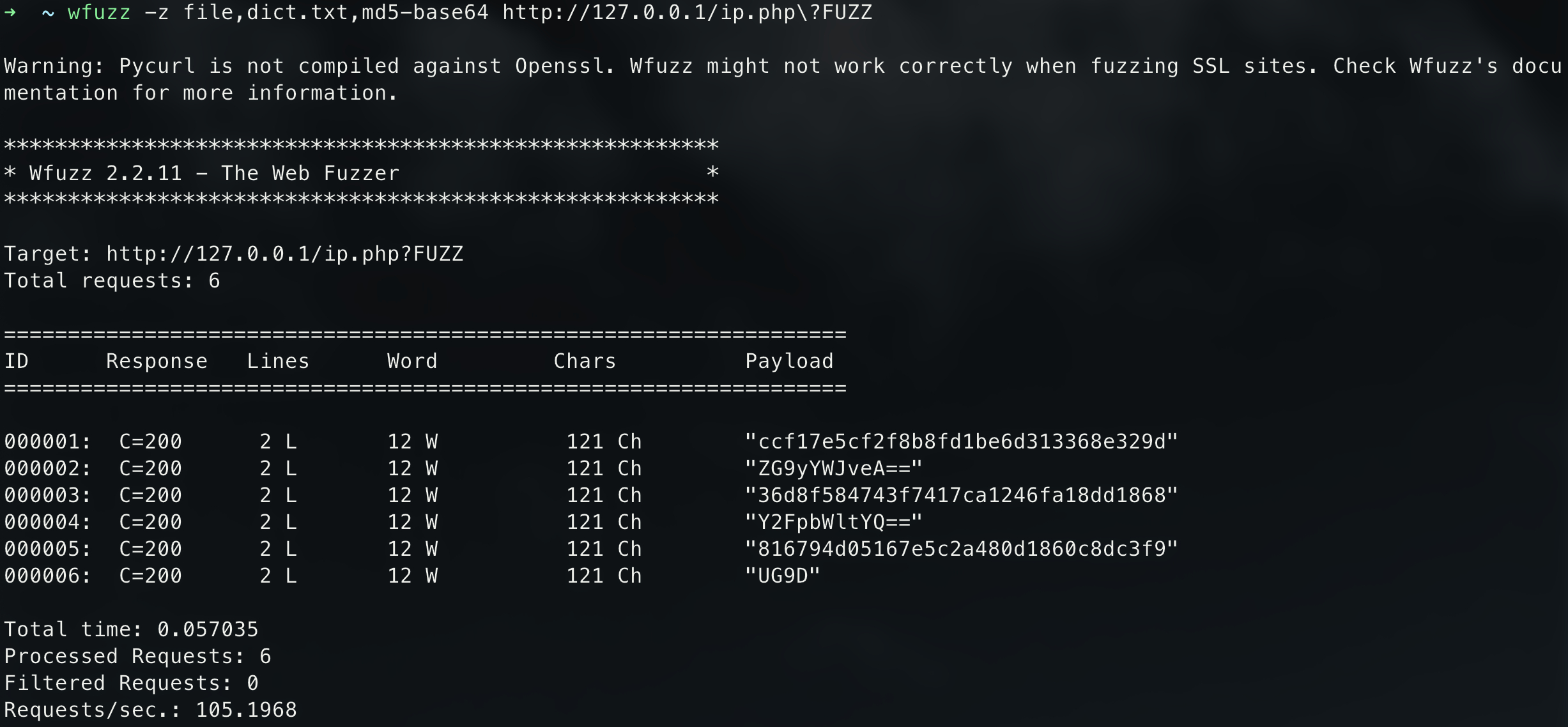
多次转换,使用一个
@号分隔的列表来按照从右往左顺序多次转换(这里让传入的字典先md5加密然后base64编码)wfuzz -z file,dict.txt,base64@md5 http://127.0.0.1/ip.php\?FUZZ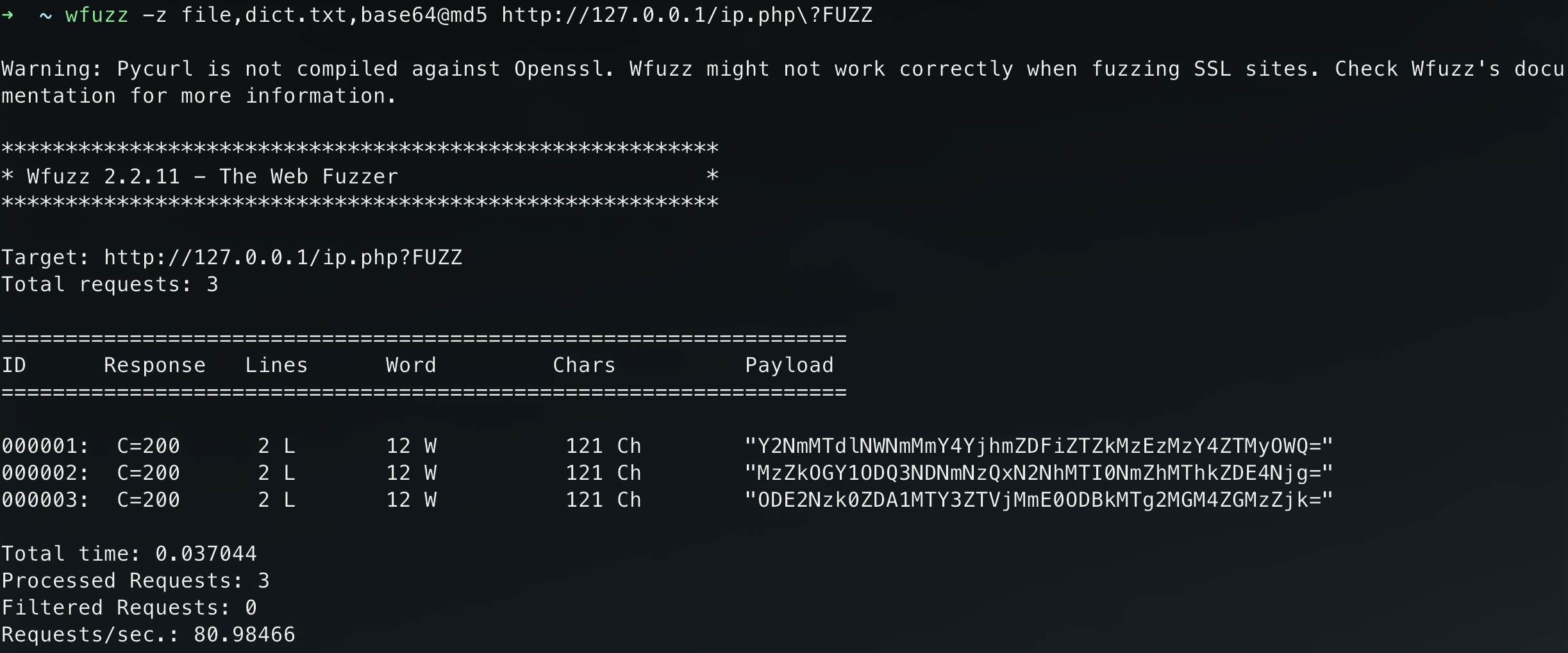
2.3.3 Scripts
之前说了wfuzz支持插件,其本身也有很多插件,插件大部分都是实现扫描和解析功能,插件共有两大类和一类附加插件:
- passive:分析已有的请求和响应(被动)
- active:会向目标发送请求来探测(主动)
- discovery:自动帮助wfuzz对目标站进行爬取,将发现的内容提供给wfuzz进行请求
Wfuzz默认自带脚本如下:
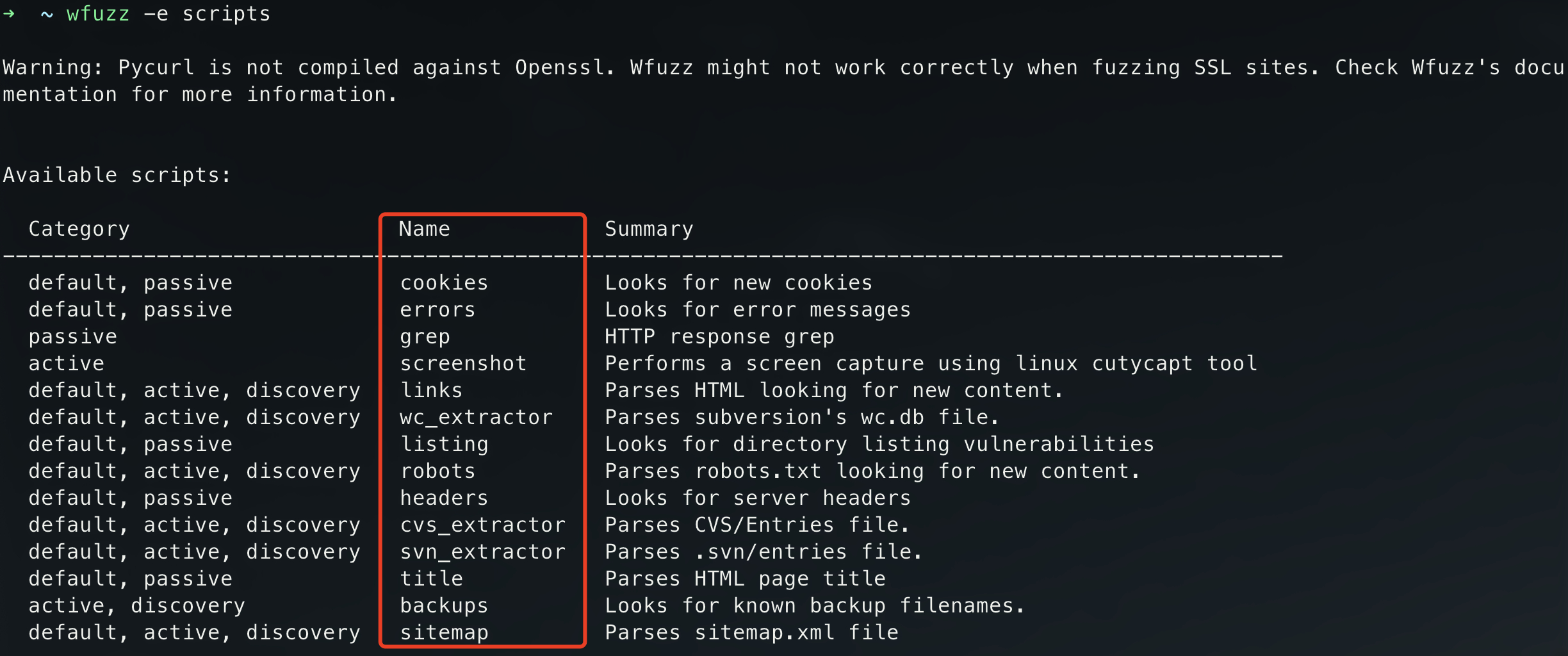
使用Scripts
我想使用Scripts中的backups模块,可以先试用--script-help参数来看如何关于这个模块的信息:
1 | wfuzz --script-help=robots |
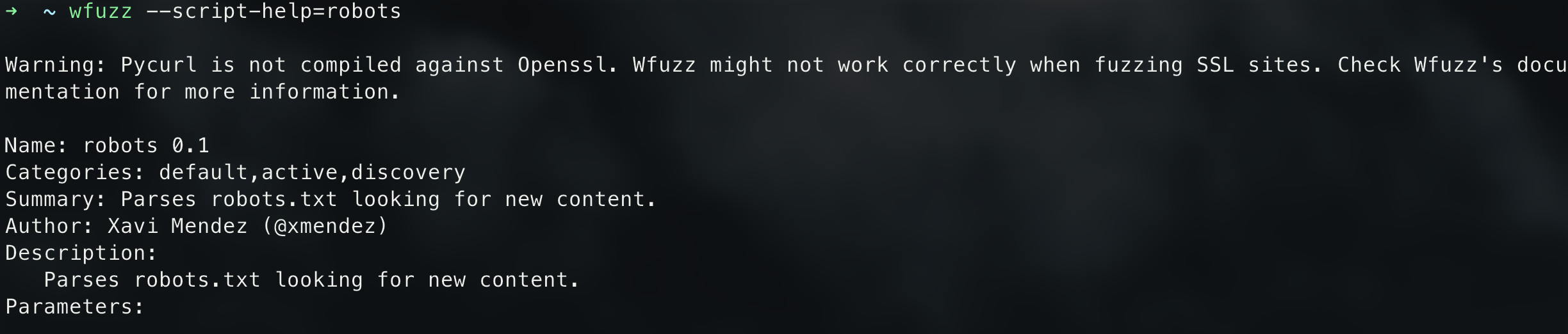
从如上结果中可以知道这个模块不需要设置参数,该模块解析robots.txt的并且寻找新的内容,,至于到底寻找什么,就需要动手实践下了~
在本地建一个robots.txt:
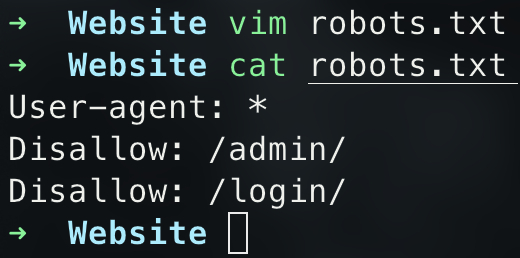
使用如下命令:
1 | wfuzz --script=robots -z list,"robots.txt" http://127.0.0.1/FUZZ |
--script是使用脚本模块的参数,这时候就有个疑惑命令为什么要加上list呢?因为在这里robots脚本只是解析robots.txt规则的,所以你需要告诉wfuzz去请求哪个文件而这里我写的就是robots.txt就可以解析(假设 http://127.0.0.1/t.txt 的内容也是robots的就可以写成这样的命令wfuzz --script=robots -z list,"t.txt" http://127.0.0.1/FUZZ )
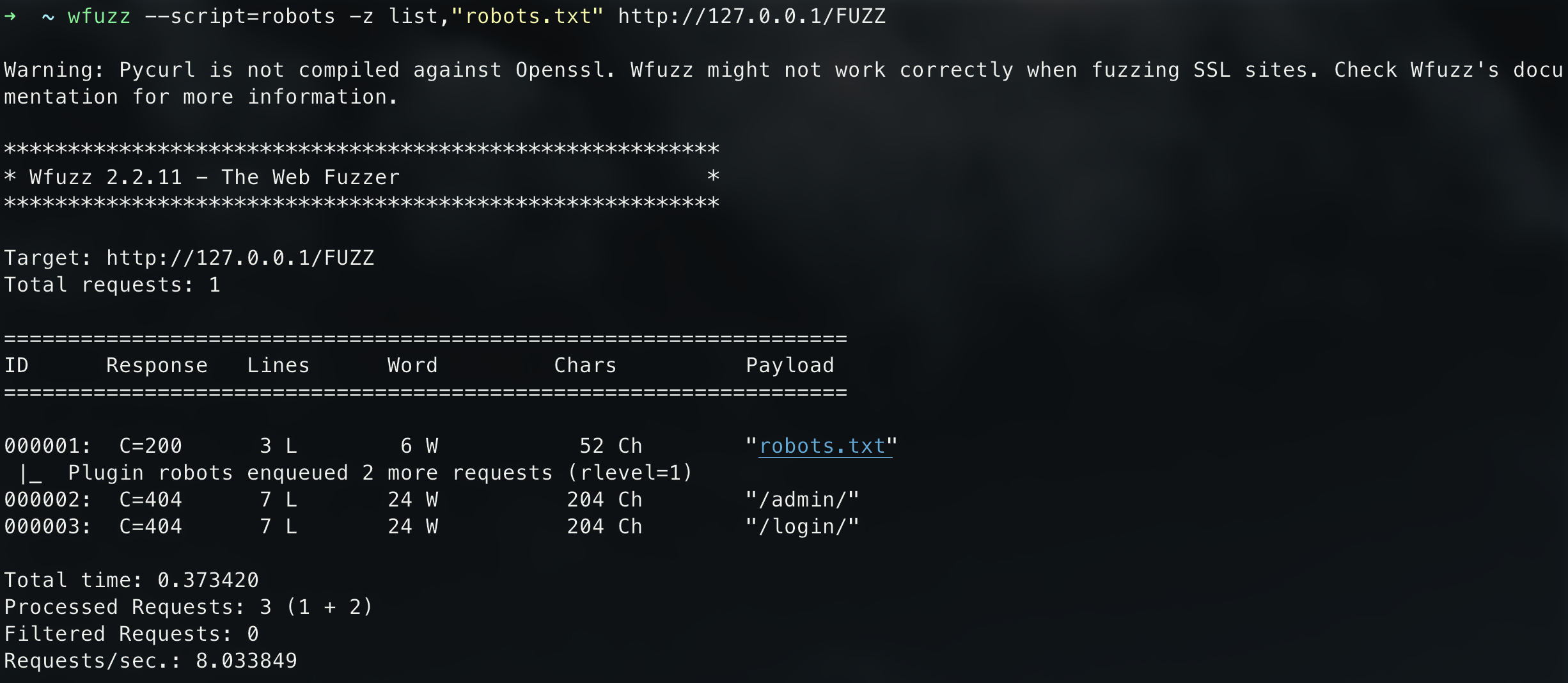
从如上图中得知wfuzz解析robots.txt的内容然后请求解析之后获得的路径。
自定义插件
使用wfuzz可以自己编写wfuzz插件,需要放在~/.wfuzz/scripts/目录下,具体如何编写可以参考已有的插件:https://github.com/xmendez/wfuzz/tree/master/src/wfuzz/plugins/scripts
2.3.4 技巧
Recipes
Wfuzz可以生成一个recipes用来保存命令,方便下次执行或者分享给别人。
生成一个recipes:
1 | wfuzz --script=robots -z list,"robots.txt" --dumo-recipe outrecipe URL/FUZZ |
使用某个recipes:
1 | wfuzz --recip outrecipe |
网络异常
Wfuzz扫描的时候出现网络问题,如DNS解析失败,拒绝连接等时,wfuzz会抛出一个异常并停止执行使用-Z参数即可忽略这些错误继续执行。
出现错误的payload会以返回码XXX来表示,Payload中还有出现的错误信息。
超时
使用wfuzz扫描会遇到一些响应很慢的情况,wfuzz可以设置超时时间。
参数--conn-delay来设置wfuzz等待服务器响应接连的秒数。 参数--req-delay来设置wfuzz等待响应完成的最大秒数。
结合BurpSuite
从Burp的LOG文件中获取测试的URL地址:
1 | wfuzz -z burplog,"1.burp" FUZZ |
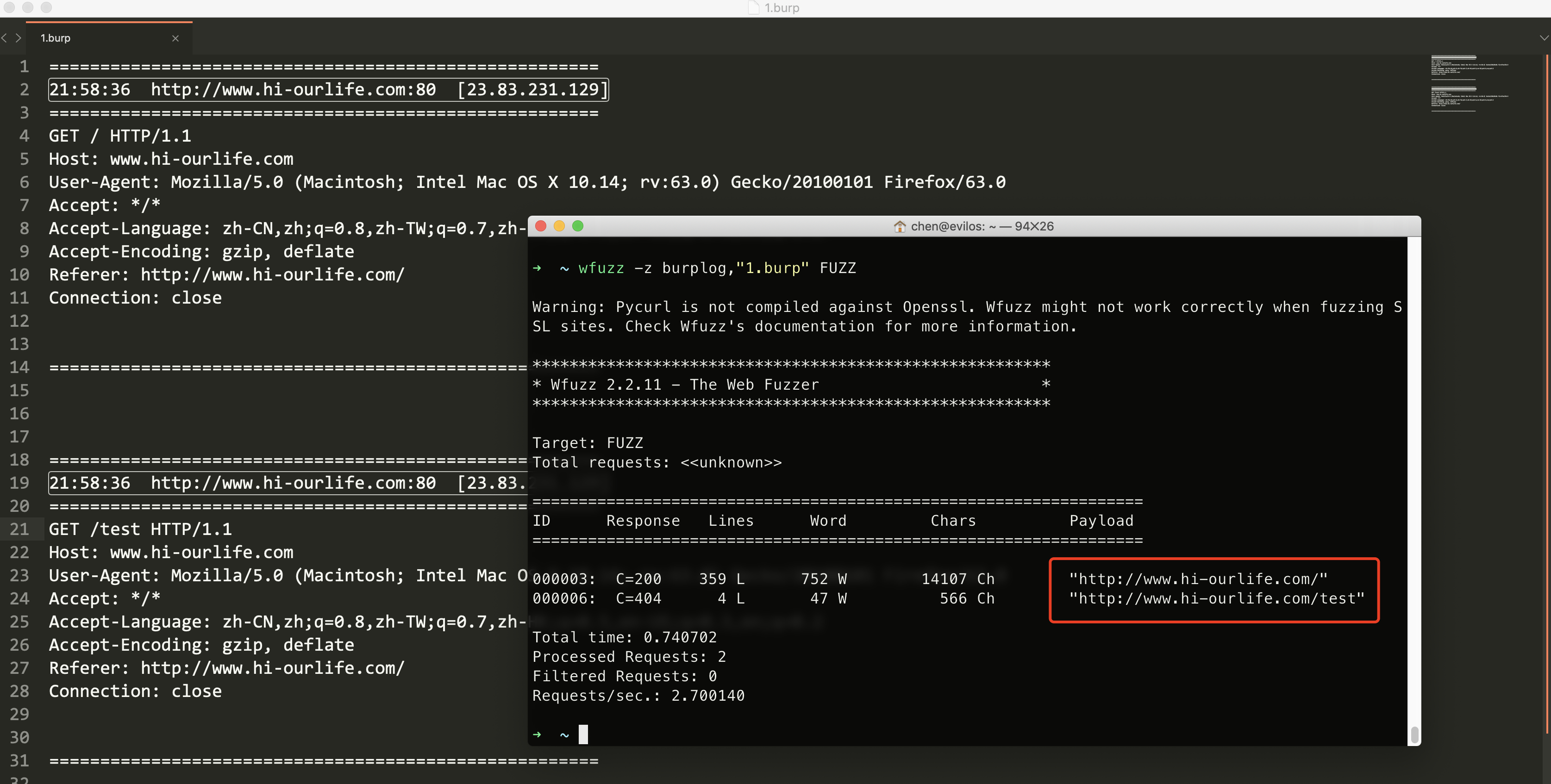
还有能够读取burpsuite保存的state:
1 | wfuzz -z burpstate,a_burp_state.burp FUZZ |
2.3.5 过滤器
这里篇幅太长,建议综合参考 https://github.com/xmendez/wfuzz/blob/18a83606e3011159b4b2e8c0064f95044c3c4af5/docs/user/advanced.rst 就不一一写出来了。
wfuzz内容转自:https://gh0st.cn/archives/2018-10-28/3
reference: